NHN의 AI Human 기술을 소개합니다
조민기 2024-04-23
NHN AI 팀에서는 AI Human이 말하는 영상을 생성하는 기술을 개발하고 있습니다.
AI Human 영상을 생성하기 위해선 우선 텍스트로 음성을 합성하는 음성합성 기술과, 이 음성을 입력으로 받아 말하는 영상 이미지를 만드는 영상합성 총 2가지 종류의 기술이 필요합니다. 그 중 음성 합성과 관련된 영상은 https://ai.nhncloud.com/62 이 링크의 글에서 정리하고 있으며 이번 포스팅에서는 후자의 영상 합성과 관련된 기술을 소개하고, 이후 발전 및 개선된 연구들을 다뤄보려고 합니다.
Synthesizing Obama
오바마 영상합성 기술
2017년 컴퓨터 그래픽스 학회인 SIGGRAPH 에서 오바마의 딥페이크 영상을 음성만으로 생성할 수 있는 기술이 등장하였습니다. 당시 CycleGAN 등 이미지 생성과 관련된 기술들이 공개되던 시기에 이미지 생성보다 더욱 고난도의 기술을 요구하는 영상합성 기술이 상당히 정교하고 놀라운 퀄리티로 공개되어 상당한 주목을 받았습니다.
뿐만 아니라 기술의 기능적 활용성 또한 주목을 받았습니다. 기존의 주류 딥페이크 기술인 Face swap 방식의 경우 원본 위조영상을 연기해줄 배우가 베이스가 될 모션을 연기해주고 얼굴만 교체하는 방식이었습니다. 덕분에 영화에서 화려한 액션을 선보이는 배우의 얼굴을 바꾸는 등의 활용은 가능하지만, 베이스가 될 영상의 정해진 대사만 가능할 뿐 내가 원하는 말을 배우가 말하도록 영상을 생성하는 활용은 Face swap 방식으로는 불가능합니다.
하지만 위 오바마 영상합성 기술은 구조상 텍스트 한 줄만 있으면 누구나 쉽게 오바마 전대통령이 내가 입력한 텍스트의 대사를 말하는 딥페이크 영상을 생성할 수 있었습니다. 합성영상을 자세히 살펴보지 않으면 어느 쪽이 위조 영상인지 알아차리기 힘들 정도의 퀄리티의 영상을 텍스트 타이핑만으로 생성할 수 있는 기능적인 측면이 매력적이라 해당기술은 많은 주목을 받았습니다.
Deep Fake 기술은 위에서 언급한 Face swap 방식을 포함하여 여러가지 방식의 기술들이 연구되고 있으며, 이번 글에서는 위의 Synthesizing Obama에서 사용된 방식의 기술들에 대해 다뤄보겠습니다.
AI Human 생성 기술 개요
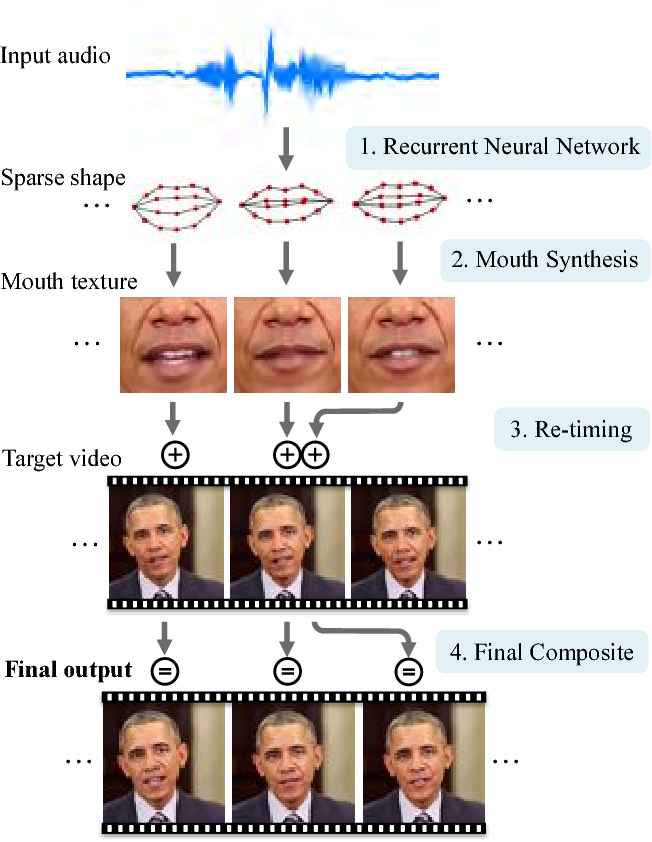
오바마 합성영상의 기술에서 주목할 점들은 크게 2가지로 나눌 수 있습니다. 첫번째 음성을 입력으로 받아 이에 맞는 입모양을 만들어내는 모델과, 두번째로 이 입모양을 영상의 인물의 입처럼 이미지를 합성해내는 모델입니다.

첫번째 입모양 추론 모델은 음성입력을 받고 이를 얼굴 랜드마크중 입모양을 결정하는 몇가지 랜드마크의 좌표를 아웃풋으로 출력하여 해당 발음에 적합한 입모양을 만들어내는 역할을 합니다. 음성이라는 시계열 데이터를 입력으로 받아 해당 길이에 맞는 입모양 시퀀스를 아웃풋으로 출력하는 형태로, 위 오바마 합성기술 모델에서는 RNN 구조의 네트워크가 채택되었습니다. 입모양 랜드마크 데이터는 입모양을 결정하는 20여개의 정해진 랜드마크 포인트들의 절대좌표를 예측하거나, 전 프레임의 좌표로부터 이동값을 나타내는 벡터를 추론하는 등의 방식이 사용됩니다.

두번째 영상 합성 모델의 경우 입모양 랜드마크들을 실제 입 이미지로 전환하는 태스크로, 이는 Pix2Pix부터 발전된 Image transfer 기술들이 사용되었습니다. 다만 Image transfer 기술을 그대로 사용하여 수백프레임의 연속된 이미지 시퀀스인 동영상을 합성한다면, 프레임간의 연속성이 없어 영상이 뚝뚝 끊기는 현상이 생길 수 있습니다.
이런 Temporal consistency 문제를 해결하고 자연스럽고 부드러운 영상을 만들기 위해 5프레임 이상 연속된 영상 프레임을 합성하는 모델을 학습하거나, 혹은 비디오 처리를 위한 Optical flow가 도입되는 등 딥러닝 모델 자체를 비디오생성에 맞게 개선하는 시도들이 있었습니다. 또 딥러닝 관련 접근이 아닌 고전적인 컴퓨터 그래픽스 기술을 사용하여 영상을 가다듬는 후처리를 하는 등의 해결방법도 도입되었습니다. 가령 이 오바마 합성 논문에서는 말하는 오바마 이미지들을 합성한 뒤에 자연스러운 영상 모션으로 보여질 수 있도록 Re-timing 과정으로 키프레임간 간격을 재조정한 뒤 키프레임간 사이 프레임들을 정해진 수만큼 생성하여 자연스러운 영상을 다시 제작하였습니다.
여기까지가 오바마 합성 기술의 개요이며, 이후 이를 개량 및 발전시키기 위한 많은 연구들이 이루어졌습니다. 오바마 합성 기술처럼 입술 랜드마크, 입모양을 추론하는 모델과 영상을 합성하는 모델 두 단계로 분리하여 각각 학습을 하는 기술들도 많이 개발되었지만, 추후에는 이 두 태스크를 합쳐 음성입력 -> 발화 영상출력을 End-to-End로 수행하는 통합형 모델도 개발이 되었습니다.
또한 위 입모양 생성 모델과 같은 시계열 데이터를 사용하는 태스크들은 당시에는 주로 RNN 혹은 LSTM등의 구조가 많이 사용되었으나, 2017년부터 주목받으며 급속도로 퍼져나간 트랜스포머 모델이 이런 시계열 데이터 추론모듈을 대체하며 AI Human 기술들이 개선되기도 하였습니다. 덕분에 위 기술이 학습데이터로 오바마 영상 10시간 이상을 필요로 했던 것을 최근에는 학습데이터 1시간이하, 심지어는 10분 남짓 분량의 학습데이터만으로도 상당한 퀄리티로 모델학습을 할 수 있게 되었습니다.
타겟 인물의 학습데이터가 필요없는 모델
오바마 합성 기술의 한계점들중 하나는 영상을 합성하고싶은 타겟 인물의 말하는 영상 데이터가 학습용으로 확보되어야 한다는 점이었습니다. 해당 모델로는 사용자가 영상데이터를 확보하지 못한 인물에 대해서는 AI Human 영상을 만들 수 없으므로 데이터를 확보할 수 없는 인물이나 실존하지 않는 인물 혹은 캐릭터, 가령 애니메이션 겨울왕국의 캐릭터같이 말하는 영상 데이터를 확보하기 힘든 인물에 대해선 적용할 수 없는 한계가 있습니다.
또, 배우를 섭외하더라도 학습데이터 확보를 위해 10시간이나 촬영을 해야한다는 점 역시 특수한 경우가 아니면 데이터를 준비하는 과정조차 상당히 힘든 작업입니다. 따라서 우리가 데이터를 확보하지 못한 인물에 대해서 AI Human을 만들 수 있는 기술에 대해 많은 연구가 이뤄졌고, 지금부터 소개할 Wav2Lip이 그런 기술 중 하나입니다.

Wav2Lip에선 한명의 인물이 아닌 BBC 방송에서 등장했던 수많은 인물들의 말하는 영상 데이터를 전부 학습하였습니다. 기본적인 구조는 학습데이터 영상 이미지의 입을 포함한 아래 절반을 지우고, 음성과 함께 지워진 영상을 입력으로 받아 완성된 영상을 합성해내는 방식으로 학습을 진행합니다. 수천명이 넘는 인물의 수백시간이 넘는 영상데이터가 활용되었고 학습과정을 통해 모델은 다양한 인물들의 음성을 이해하여 인코딩하고, 음성에 맞는 입모양을 최종 영상으로 합성해내는 방법을 배우게 됩니다.
이러한 방식으로 학습한 결과 단일 인물이 아닌 다수의, 심지어 학습데이터에 포함되지 않은 인물에 대해서도 말하는 영상을 합성할 수 있게 되어 임의의 인물에 대한 데이터가 없어도 AI Human 영상을 합성할 수 있게 됩니다.

Harry Potter by Balenciaga 의 장면
최근엔 배우섭외의 초상권 및 여러 법적 제도적 이슈, 혹은 단순히 사용자의 기호 및 목적에 따라 이러한 타겟인물의 학습데이터가 없이도 동작할 수 있는 모델들에 대한 연구가 많이 이뤄지고 있습니다. NHN 역시 사용자들의 목적에 맞게 새로운 경험을 제공하기 위한 AI Human 서비스를 개발 및 연구중에 있으니 앞으로 많은 기대 부탁드립니다.


![[클라우드 용어집] AX란?(개념, 필요성, 동향, DX와의 차이)](/brand_/storyboard/2025/202510211047061.png)


