음악 생성 기술의 혁신: Diffusion 모델과 AudioGPT, Stable Audio 소개
김경훈 2024-08-22
최근 몇 년간 인공지능(AI) 기술이 급격히 발전하면서 다양한 분야에서 새로운 혁신이 일어나고 있습니다. 특히 생성형 AI는 단순한 텍스트 생성에 그치지 않고 이미지, 영상, 음악, 오디오까지 창작의 영역을 확장하면서 큰 주목을 받고 있는데요.
그 중에서도 음원 시장은 특히 새로운 경쟁의 중심지로 떠오르고 있습니다. 생성형 AI 기술은 이제 작곡, 작사, 믹싱 등 음악 제작의 모든 과정에서 활용될 정도로 발전했으며, 그 결과물은 인간이 만든 음악과 비교해도 손색이 없을 정도입니다.
실제로 생성형 인공지능(AI)으로 작곡한 노래가 독일 대중음악 차트 48위에 오르고, 중국에서는 AI 작곡 콘서트가 개최되는 등 생성형 AI의 창작 활동이 화두인 가운데, 이번 글에서는 생성형 AI를 활용한 음악 생성 기술을 보다 알기 쉽게 소개 드리고자 합니다.
AI를 활용한 음악 생성: 어디까지 왔을까?

spectrogram(audio)를 생성하는 모습 (출처 : https://www.riffusion.com)
최근 들어 이미지 생성분야에서의 Diffusion model은 놀라운 성능을 보여주고 있는데요. 이제는 이미지 생성 뿐만이 아니라 오디오 생성분야에서도 diffusion model을 활용하여 고음질 오디오를 생성하려는 연구가 활발히 진행되고 있습니다. 텍스트를 입력받아 오디오 및 음악을 만들 수 있으며, 이러한 종류의 AI 모델은 일반적으로 "Text to Audio/Music" 또는 "Audio/Music Generation" 모델이라고 부릅니다.
사실, 인공지능이 오디오를 생성하는 연구는 이미 오래전부터 이루어져 왔습니다. 예를 들어, 아마존의 알렉사(Alexa)가 내는 음성이나, 오픈AI의 주크박스(Jukebox) 같은 AI 음악 시스템이 그 대표적인 예입니다. 그러나 고품질의 다양한 오디오를 생성하는 데는 여전히 한계가 있었습니다. 이를 개선하기 위해 최근에는 Diffusion 모델을 활용한 기술 개발이 활발히 이루어지고 있습니다.
Riffusion: 이미지 생성 모델로 음악을 만들다
Riffusion은 원래 이미지 생성에 사용되던 Stable Diffusion 모델을 활용해 음악을 생성하는 기술입니다. 이 모델은 소리를 '스펙트로그램'이라는 이미지로 변환해, 마치 이미지를 다루듯이 오디오를 다룹니다. 스펙트로그램은 시간에 따라 주파수와 음량을 나타내는 2차원 이미지입니다.
이 기술을 통해 서로 다른 음악 스타일을 결합하거나, 음악의 특정 부분을 수정하는 등 다양한 방식으로 음악을 창작할 수 있습니다.
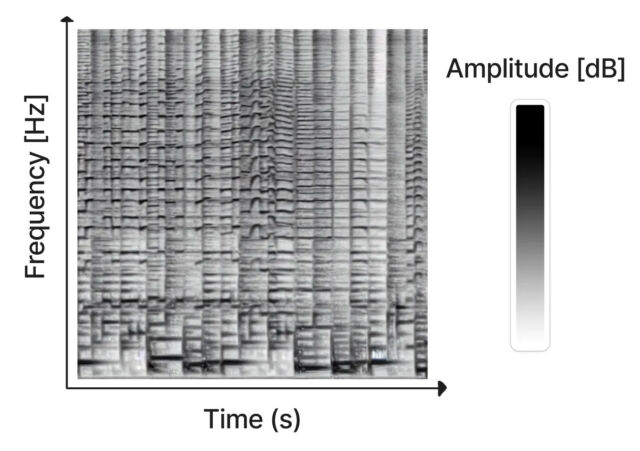
스펙트로그램은 2차원 이미지에서 시간, 주파수 및 진폭을 나타낸다. (출처 : https://www.riffusion.com)
또한 서로 다른 스타일을 결합하거나, 한 스타일에서 다른 스타일로 부드럽게 전환하거나, 기존 사운드를 수정하여 개별 악기의 음량 증가, 리듬 변경, 악기 교체와 같은 다양한 기능이 가능합니다.
ChatGPT의 열풍, AudioGPT의 등장
최근 ChatGPT와 같은 대규모 언어 모델이 인기를 끌면서, 이를 음악과 음성 생성에 적용한 AudioGPT가 등장했습니다. 이 모델은 여러 오디오 모델을 연결하여 음악과 음성을 이해하고 생성하는 다양한 작업을 수행할 수 있습니다. 예를 들어, 입력된 텍스트를 바탕으로 사용자의 의도를 파악하고, 적절한 오디오를 생성하는 방식입니다. 이러한 기술은 단순한 음악 생성뿐만 아니라, 대화형 인터페이스를 통해 다양한 오디오 작업을 수행할 수 있게 합니다.

multiple rounds of dialogue between humans and AudioGPT (출처: audioGPT paper(https://arxiv.org/pdf/2304.12995.pdf))
위 그림은 AudioGPT의 대화 예시입니다. 음성, 음악, 소리를 생성하고 이해하는 일련의 AI task를 다루는 것을 보여줍니다. 대화에는 오디오 정보를 처리하기 위한 여러 요청이 포함되며 AudioGPT가 현재 대화의 컨텍스트를 유지하고 후속 질문을 처리하며 사용자와 적극적으로 상호 작용함을 보여줍니다.
Stable Audio 2.0: 더 긴 음악을 생성하는 모델
Stable Audio 2.0은 stability.ai에서 공개한 최신 모델로, 단일 텍스트 프롬프트를 사용해 최대 3분 길이의 고품질 음악을 생성할 수 있습니다. 이 모델은 44.1kHz 스테레오로 높은 음질을 제공하며, 다양한 음악적 구조를 반영한 전체 트랙을 생성할 수 있습니다.
음악, 음향 효과, 단일 악기 스템을 포함한 800,000개 이상의 오디오 파일과 해당 텍스트 메타데이터로 구성된 AudioSparx 의 데이터로 학습하였고 방대한 데이터로 학습한 효과로 매우 다양하고 고품질의 음원 생성 능력을 보여줍니다.
이 플랫폼은 뮤지션과 작곡가를 위해 인트로, 절, 코러스, 아웃트로 등 다양한 섹션을 포함한 완전한 음악 작품을 만들 수 있는 확장 트랙 생성 기능을 제공합니다. 또한, 자연어 프롬프트를 통해 오디오 대 오디오 변환을 지원하며, 음향 효과 제작과 스타일 전송 기능도 탑재하고 있어 다양한 콘텐츠 크리에이터에게 유용하게 사용될 수 있습니다.
주요 기능
- 텍스트-오디오 생성: 텍스트 프롬프트로 설명하여 음악, 음향 효과 및 사운드스케이프를 생성합니다.
- 오디오-오디오 변환: 스타일 전환 및 변형을 위해 자연어 프롬프트를 사용하여 기존 오디오 샘플을 업로드하고 수정합니다.
- 확장된 트랙 길이: 일관된 음악 구조를 갖춘 최대 3분 길이의 고품질 오디오 트랙을 생성합니다.
- 상업적 사용 권리: 저작권 문제 없이 상업 프로젝트에서 생성된 오디오 콘텐츠를 사용할 수 있습니다.
- 고품질 출력: 전문적인 44.1 kHz 스테레오 형식으로 오디오를 제작하고 다운로드합니다.
아래 데모 사이트에서 직접 음원 생성 및 주요 기능들을 테스트해 볼 수 있습니다.
https://stableaudio.com/
AI 오디오의 미래
AI를 활용한 오디오 생성 기술은 빠르게 발전하고 있으며, Diffusion 모델, AudioGPT, Stable Audio 2.0 등 다양한 혁신적인 모델들이 등장하고 있습니다. 이러한 기술들은 오디오 생성의 새로운 가능성을 열어주고 있으며, 음악과 사운드 디자인 분야에서 창작의 패러다임을 바꾸고 있습니다. 다만, 이러한 발전이 저작권 문제와 어떤 식으로 조화를 이루며 법적, 윤리적 기준을 확립할지에 대한 논의는 앞으로도 지속적으로 이루어져야 할 것입니다.
참고 문헌
[1] Forsgren, S., and H. Martiros. "Riffusion-Stable diffusion for real-time music generation, 2022." URL https://riffusion. com/about.
[2] Huang, Qingqing, et al. "Noise2music: Text-conditioned music generation with diffusion models." arXiv preprint arXiv:2302.03917 (2023).
[3] Huang, Rongjie, et al. "AudioGPT: Understanding and Generating Speech, Music, Sound, and Talking Head." arXiv preprint arXiv:2304.12995 (2023).
[4] Thoppilan, Romal, et al. "Lamda: Language models for dialog applications." arXiv preprint arXiv:2201.08239 (2022).
[5] Huang, Qingqing, et al. "Mulan: A joint embedding of music audio and natural language." arXiv preprint arXiv:2208.12415 (2022).
[6] Evans, Zach, et al. "Fast timing-conditioned latent audio diffusion." arXiv preprint arXiv:2402.04825 (2024).


![[클라우드 용어집] AX란?(개념, 필요성, 동향, DX와의 차이)](/brand_/storyboard/2025/202510211047061.png)
![AI 기술 프로젝트, [자유대화 분야 연구]를 소개합니다.](/brand_/storyboard/2020/202011251320131.jpg)